Introduction to GAN (Generative Adversarial Networks)

All those people that you can see in the image above do not exist in person and are all created using StyleGAN 2. GANs have been lately too popular because of their wide applications in several fields such as computer vision, gaming, medical science, artificial intelligence, etc.
Their ability to generate such high-quality photorealistic images is something that has astonished many people over the globe. It’s too hard to differentiate between the images that they generate whether they are real or fake!
Just take some time to analyze the below gif of people who do not exist in reality.

In this article, I will be discussing the functioning of a basic GAN and its mathematics. In my upcoming articles, I will further discuss different types of GAN and its implementation using TensorFlow and PyTorch.
Generative Adversarial Networks
GAN is a type of neural networks used in deep learning for both supervised & unsupervised learning that consists of two neural networks which keep competing among themselves and it mainly comprises of these two components:
1. Discriminator
2. Generator

They are trained in an adversarial manner to generate data that are similar to the given distribution and they consist of two models as:
1. Discriminator model: It distinguishes between real and fake samples and fine-tunes its parameters through backpropagation.
0 — fake
1 — original
It works similarly to the classifier models as it differentiates between different classes.
2. Generative model: The role of it is to produce fake samples which are similar to the real sample such that it fools the discriminator.
Note: Each is held constant while the other is trained.
Training GAN
- At first, the discriminator is trained by keeping the generator fixed (no forward & backward propagation is done).
- Once the discriminator is trained, then the generator is trained to generate fake images to fool the discriminator.
- Step 1 & 2 are repeated to a point where the discriminator cannot distinguish between real(1) & fake(0) images and outputs a value of 0.5
Notations


Loss function in GANs
The binary cross-entropy loss is given as:
L(ŷ,y) = [ y*log(ŷ) + (1-y)*log(1- ŷ) ]
Data coming from the real distribution pdata(x) have label value 1 for y & data of ŷ is D(x). Plugging them into binary cross-entropy loss we derive:
L(D(x), 1) = log(D(x)) → A
And, for data coming from generator have label value 0 and data of ŷ is G(D(z)). Plugging them into binary cross-entropy loss we derive:
L(D(G(z)), 0) = log(1- D(G(z))) → B
Objective of Generator & Discriminator

Discriminator’s objective is to distinguish between fake & real data and for that it should maximize the loss by maximizing the values for the above two equations A & B written as:
max{ log(D(x)) + log(1- D(G(z))) }
The generator’s objective is to fool the discriminator and for that it should minimize the loss by minimizing the values for A & B as:
min{ log(D(x)) + log(1- D(G(z))) }
The combined equation from the above 2 equation is:

So far, we have considered just one data point, now we take even other data points and for that, we need to calculate the expectation given as:

Optimal Discriminator
When G is fixed, the optimal discriminator is given as:

Derivation
The criterion of the discriminator is to maximize the loss from the actual equation when G is kept constant and be represented as:

Now we will work on this particular equation and for that, we need to know 1 concept which is “change of variable”.
Change of variable
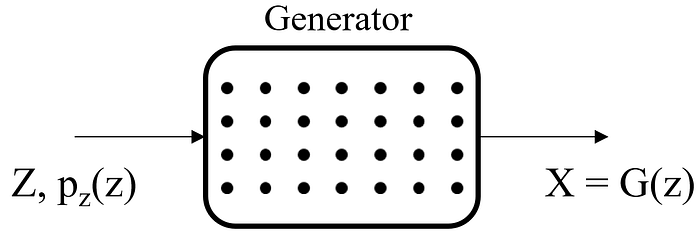

Optimal Generator
After obtaining the value for optimal discriminator the role of the optimal generator G* is to generate fake values which would be very similar to the real values i.e pg = pdata and we get the function as:
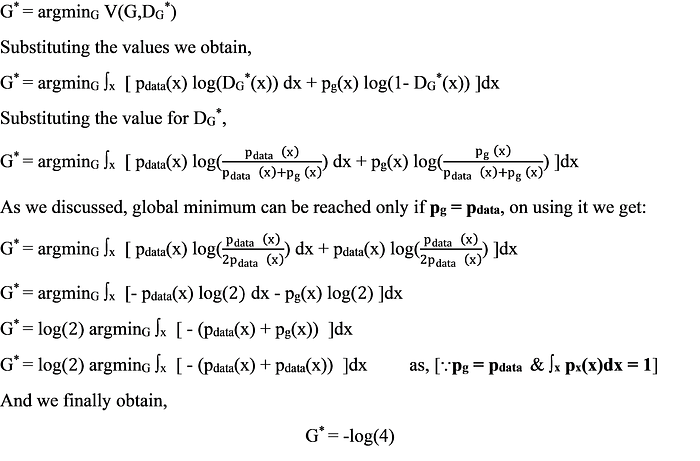
Diagrammatically
As we can see in the diagram the distributions generated aren’t similar to the true distribution from discriminator so with every iterations weights and biases are adjusted and accordingly the generated distribution becomes as close to the discriminators.

a) Poorly fit model
b) After updating D
c) After updating G
d) Both are similar
After a while, they both become similar and look the same.
Optimization of Loss Function
Optimization of the loss function is necessary to adjust the weights and biases of the generator and discriminator during the backpropagation. According to the paper published by Ian Goodfellow 2014, minibatch stochastic gradient descent is used and the equations are as:

Note: Refer to the notations mentioned in the top and here we take it for multiple points hence it’s it’s x(i) & z(i).
Limitations of GANs
1. Vanishing Gradients
Initially, the generator hasn’t learned all the parameters so the discriminator easily distinguishes between real and fake data. Discriminator gets too robust that the generator can’t further fool it and learns nothing as a derivative of the generator function is close to 0 i.e.


Due to minimization, it can’t learn much, and also the rate at which it learns is slow. Hence, we take the maximization of the generator function.

2. Mode Collapse
While training, the generator may get stuck with a setting where it keeps on producing the same output over and over again. In the below diagram we can see it starts producing similar-looking images of the same tone, lighting, posture, hair color, etc.

3. Hard to attain Nash Equilibrium
There exists no relation between discriminator & generator while updating their own weights due to which their gradients can’t guarantee a convergence. The “min max” operation causes the generator & disciminator to undermine the other leading to the zero-sum non-cooperative game where one’s loss is the other’s win and vice versa.
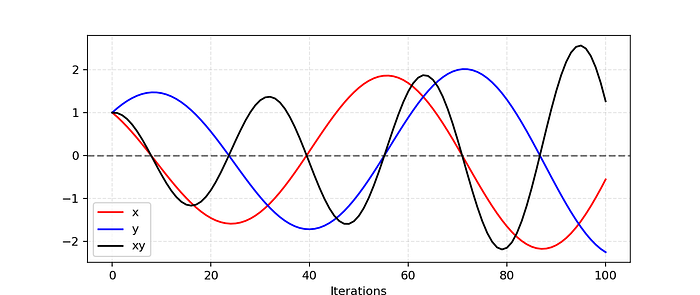
Due to this, after certain iterations, huge oscillations take place along with a lot of instability.
For info kindly refer to this: https://lilianweng.github.io/lil-log/2017/08/20/from-GAN-to-WGAN.html
4. Problem with Counting, Perspective & Global Structure
GAN has a hard time understanding the number of objects present in the image and might generate weird artifacts.
They also have problems with understanding the 3D perspective of the image and tend to generate 2D perspective images.
Lastly, they can’t understand the global structure of the image which means that there are other objects too in the image like trees, leaves, etc. and they have a tough time generating images with such structures.
That’s all about the GAN and in upcoming articles, we will further look at different types of GAN along with their implementation using TensorFlow and PyTorch. As well as, understand better methodologies to overcome the shortcomings of GAN.
AUTHOR
Sudeep Das : https://www.linkedin.com/in/sudeepdas27/
